
Ontologie-Aufbau
Semantische Suche
Visualisierung von Wortfeldern
DISCO
semantische Ähnlichkeit zwischen Wörtern abfragen

Was ist DISCO?
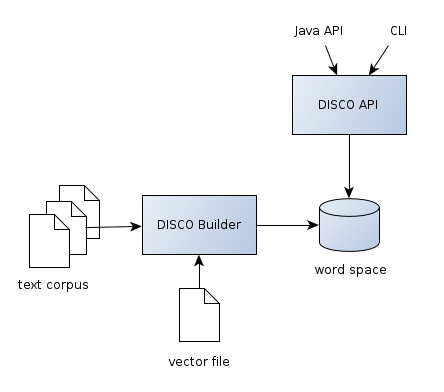
DISCO (extracting DIstributionally related words using CO-occurrences) ist eine Java-Klasse zur Abfrage der semantischen Ähnlichkeit zwischen Wörtern und Phrasen. Die Ähnlichkeiten basieren auf der statistischen Auswertung sehr großer Textmengen. Das Tool läuft auf allen gängigen Betriebssystemen, unter anderem Windows, Linux, Solaris und MacOS. DISCO besteht aus
- der DISCO API, mit der eine vorhandene Datenbank aus ähnlichen Wörtern abgefragt werden kann, und
- DISCO Builder, mit dem eine Datenbank ähnlicher Wörter aus einem Textkorpus erzeugt werden kann.
Die Java-API stellt u.a. folgende Methoden zur Verfügung:
- Semantisch ähnlichste Wörter zu einem Eingabewort ausgeben: Z.B. schüchtern → scheu hölzern nervös unbeholfen ängstlich zurückhaltend ratlos naiv steif unsicher schweigsam
- Größe der semantischen Ähnlichkeit zwischen zwei Eingabewörtern anzeigen: sim(Erdöl, Benzin) = 0,323; sim(Erdöl, Zuckerguss) = 0,016
- Kollokationen zu einem Eingabewort ausgeben: Bier → tranken trinken brauen alkoholfreien trinkt braute gebraut zapfen ausgeschenkt Oktoberfest Pilsner
- clustern ähnlicher Wörter, inklusive Ausgabe an CLUTO
- "grow set": findet weitere Wörter, die zu allen Wörtern einer Menge bedeutungsähnlich sind.
Weitere Methoden der DISCO API sind weiter unten beschrieben.
DISCO kann auch über die Kommandozeile abgefragt werden. Außerdem ist für den bekannten Ontologie-Editor Protégé ein DISCO-Plugin verfügbar.
DISCO ist in folgenden Konferenzpapieren beschrieben:
Peter Kolb. Experiments on the difference between semantic similarity and relatedness. In Proceedings of the 17th Nordic Conference on Computational Linguistics - NODALIDA '09, Odense, Denmark, May 2009.
Peter Kolb. DISCO: A Multilingual Database of Distributionally Similar Words. In Tagungsband der 9. KONVENS, Berlin, 2008.
Überblick
Die DISCO-API benötigt eine Datenbank mit Wortähnlichkeiten. Diese Datenbank wird auch
Wortraum genannt (engl. "word space"). Ein Wortraum beinhaltet für jedes Wort einen
Wortvektor und (abhängig von der Art des Wortraums) die semantisch ähnlichsten Wörter
(diejenigen, deren Wortvektoren dem Wortvektor des Ausgangswortes am Ähnlichsten sind).
Seit der DISCO-Version 2.0 gibt es zwei Arten von Worträumen:
- COL: Worträume des Typs COL beinhalten nur die Wortvektoren aber nicht die Listen der ähnlichsten Wörter zu jedem Wort. Deswegen arbeiten einige der Methoden der DISCO-API nicht mit Worträumen des Typs COL. COL-Worträume haben den Vorteil, dass sie schneller zu erzeugen sind und eine geringere Größe haben.
- SIM: Worträume des Typs SIM enthalten sowohl die Wortvektoren als auch die Listen der ähnlichsten Wörter zu jedem Wort.
Mit dem DISCO Builder können Sie Worträume aus Ihren Textkorpora erzeugen. Darüberhinaus ermöglicht der DISCO Builder Vektordateien, die mit word2vec oder GloVe erzeugt wurden, in einen DISCO-Wortraum zu konvertieren. Für mehrere Sprachen sind fertige Worträume auf der Download-Seite verfügbar.
Anwendungen
Die Anwendungsmöglichkeiten der semantischen Ähnlichkeit nach DISCO sind äußerst vielfältig und erstrecken sich über alle Bereiche der Sprachtechnologie. Im folgenden sind einige Einsatzgebiete aufgeführt:
- Übersetzung: kontextsensitive Übersetzung. Beispiel: Die Bank sperrt das Konto. Ein Wörterbuch liefert: Bank → bank, bench und Konto → account. DISCO liefert die Ähnlichkeiten: sim(bank, account) = 0,124 und sim(bench, account) = 0,045, so dass bank als im Satzkontext korrekte Übersetzung ausgewählt werden kann.
- Suchmaschinen: assoziative Suche mit Hilfe semantisch ähnlicher Begriffe; automatische Suchtermerweiterung.
- E-Learning: Generieren von (zweisprachigen) Wortfeldern zu einem Sachgebiet.
- kontextsensitive Rechtschreibkorrektur: Gewichtung von Korrekturvorschlägen nicht nur nach zeichenbasierter Ähnlichkeit, sondern auch nach semantischer Ähnlichkeit mit dem Kontext.
- kontextsensitiver Thesaurus: in den Kontext passende Synonyme vorschlagen.
- Ontologieaufbau: DISCO liefert semantisch ähnliche Wörter zu einem Ausgangswort, die nur noch nach Art der Ähnlichkeitsbeziehung (Synonym, Ober-/Unterbegriff, Gegenbegriff usw.) klassifiziert werden müssen. Für den bekannten Ontologie-Editor Protégé ist ein DISCO-Plugin verfügbar.
- Textzerlegung: Zerlegen von Texten in inhaltlich zusammenhängende Abschnitte (Text-Tiling).
- Automatische Spracherkennung und OCR: Aufbau klassenbasierter Sprachmodelle.
Referenzen
Eine Liste wissenschaftlicher Artikel in denen DISCO verwendet wird, finden Sie auf der Referenzen-Seite.
Verfügbare Sprachen
DISCO benötigt für jede Sprache einen Index mit Daten. Diese Sprachdaten werden auf
der Grundlage sehr umfangreicher elektronischer
Textsammlungen (Korpora) mittels statistischer
Verfahren automatisch erstellt.
Die Sprachdaten können hier heruntergeladen werden.
Zur Zeit sind Daten für folgende Sprachen verfügbar:
Arabisch
Deutsch
Englisch
Französisch
Italienisch
Niederländisch
Russisch
Spanisch
Tschechisch
Download und Installation
- Schritt 1: Laden Sie disco-2.1.jar herunter.
- Schritt 2: Laden Sie einen der Worträume für die gewünschte Sprache herunter.
- Schritt 3: DISCO-Abfrage über die Kommandozeile:
java -jar disco-2.1.jar WORTRAUMVERZEICHNIS -bn Haus 12
gibt die zwölf semantisch ähnlichsten Wörter zu Haus aus.
Sie benötigen eine Java-Laufzeitumgebung. Sollte auf Ihrem Rechner kein Java installiert sein, können Sie es bei www.java.com herunterladen.
Aufruf über Kommandozeile
DISCO kann über die Kommandozeile abgefragt werden. Dazu geben Sie ein:
java -jar disco-2.1.jar WORTRAUMVERZEICHNIS OPTION
Die möglichen Optionen sind:
-bn WORT N: gibt die N semantisch ähnlichsten Wörter zu WORT aus. Beispiel:
-bn Maus 10 → Tastatur Joystick Ratte Mäuse Trackball Mouse Micky Goofy Tasten
Bildschirm.
-bc WORT N: gibt die N signifikantesten Kollokationen zu WORT aus. Beispiel:
-bc Urteil 7 → BGH fällen vollstreckt BVerwG Verwaltungsgerichts lautete
rechtskräftig.
-s WORT1 WORT2 SIM-MEASURE: gibt den Wert der semantischen Ähnlichkeit erster Ordnung zwischen den
Eingabewörtern aus (Wert zwischen 0 und 1).
-s2 WORT1 WORT2: gibt den Wert der semantischen Ähnlichkeit zweiter Ordnung zwischen den
Eingabewörtern aus (Wert zwischen 0 und 1).
-cc WORT1 WORT2: gibt den gemeinsamen Kontext der beiden Eingabewörter aus.
-f WORT: gibt die Korpushäufigkeit von WORT aus.
-n: gibt die Anzahl der abfragbaren Wörter aus.
-wl DATEI: gibt die Wortfrequenzliste aller Wörter im Sprachdatenpaket in die DATEI aus.
Weitere Optionen werden angezeigt, wenn Sie disco-2.1.jar ohne Parameter aufrufen.
Java-API
DISCO kann über eine Java-Schnittstelle (API) in eigene Anwendungen integriert werden. Die Java-API stellt verschiedene Methoden bereit, um semantisch ähnliche Wörter, semantische Wortähnlichkeiten, Kollokationen, Korpusfrequenzen usw. abzufragen. Eine Beschreibung finden Sie in der API-Dokumentation (javadoc).
Die folgende Java-Klasse enthält Beispielcode, der zeigt, wie man die DISCO Java-API benutzt: UseDISCO.java
Lizenzbedingungen
Die DISCO-API ist unter der Apache License, Version 2.0 frei verfügbar und Open Source.
Der DISCO Builder ist unter der Creative Commons Attribution-NonCommercial-Lizenz verfügbar.
Die meisten Worträume stehen unter der Lizenz Creative Commons Attribution, einige auch unter Creative Commons Attribution-NonCommercial.
Wenn Sie Interesse am kommerziellen Einsatz des DISCO Builders oder eines Wortraums haben, der nicht unter der Creative Commons Attribution-Lizenz verfügbar ist, kontaktieren Sie bitte Peter Kolb (peter.kolb@linguatools.org). Auf Anfrage erstellen wir auch Worträume für die von Ihnen gewünschten Fachgebiete oder Sprachen.
Danksagung
DISCO verwendet den Lucene-Index.
Die DISCO-Sprachdaten wurden teilweise auf der Grundlage von folgenden frei verfügbaren
elektronischen Textsammlungen erstellt:
- die internationalen Versionen der Wikipedia
- das Europarl-Korpus
- das JRC-ACQUIS-Korpus
- das deutsche und englische Projekt Gutenberg.